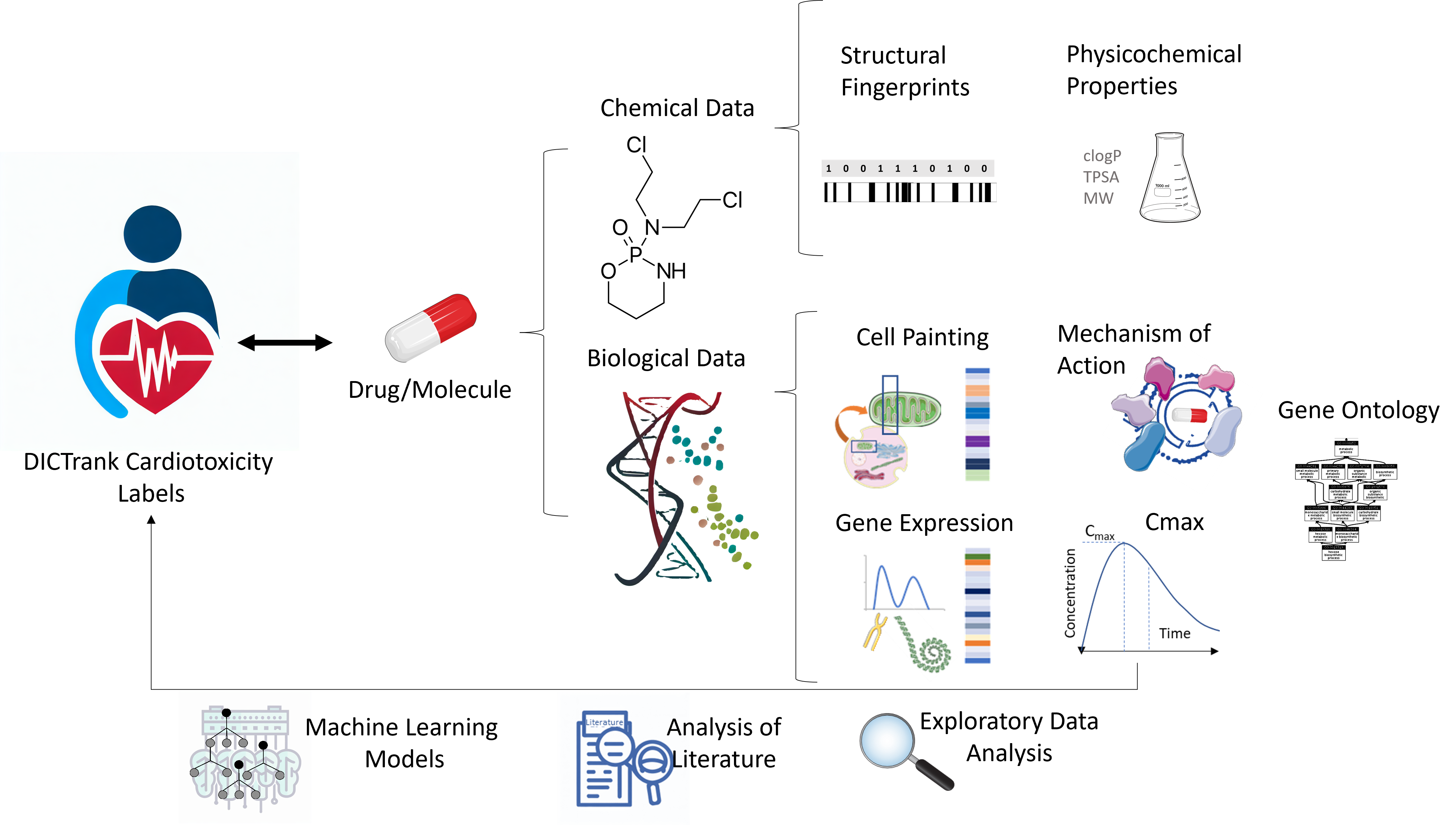
DICTrank
Dataset
Curated DICTrank dataset from FDA with standardized SMILES, chemical names, and DICTrank labels and concern categories for 1020 FDA-approved/ investigational/ experimental/ withdrawn drugs. The original paper from the FDA can be found here.
Download csv.gz (110 kB) DICTrank
Ambiguous Compounds
Curated DICTrank dataset from FDA with standardized SMILES, chemical names, and DICTrank labels and concern categories for 82 compounds labeled ambiguous in the original paper. The predictions for these compounds from models in this study are also annotated in this dataset.
Download csv (31 kB) CellScape Predicted
Targets Dataset
1893 predictions for 817 unique targets (inhibition/antagonism) and concentration combinations (0.1, 1, 10, and 100uM) for all compounds in the DICTrank dataset. Predictions are obtained using CellSpace (IgnotaLabs). For details on CellScape, visit IgnotaLabs
Download zip (6.5 MB) Mechanism of
Action Dataset
264 binary encoded MOAs and 551 known target annotations for compounds in the DICTrank dataset. Annotations are obtained from the Drug Repurposing Hub from the Broad Institute
Download csv.gz (158 kB) Cell Painting
Dataset
Contains 1783 Cell Painting features for all compounds in the DICTrank dataset. For details see original paper
Download csv.gz (215 MB) Gene Expression
Dataset
Gene Ontology
Dataset
Pharmacokinetic Property
Cmax Dataset
Contains the maximum total and unbound concentration of a drug in plasma for approximately 700 compounds that are present in the DICTrank dataset. For curation methodology, see original paper.
Download csv.gz (70 kB)SIDER dataset
Curated SIDER dataset with all side effects and standardized SMILES. For details see MoleculeNet.
Download csv.gz (128 kB)